全托管服务 紫光云消息队列Kafka有专门经验丰富的运维团队进行部署和维护,用户只需专注于业务本身,支持对实例和节点进行巡检、监控。
|
弹性扩展 用户可以按需自动扩展队列,按需计费,不会造成资源的浪费。
|
高性能 毫秒级消息投递;支持亿级消息堆积,且不影响队列性能。
|
独占式体验 紫光云消息队列Kafka实现物理隔离,实例之间互不影响,提供多种规格供用户选择,即开即用。
|




支持用户只需要在实例管理界面点击申请按钮,提交订单。后台将在几分钟内自动创建部署完成一整套Kafka实例。
可提供多种不同的规格,满足用户不同需求,用户可自行选择适合自己的规格。
高吞吐量,低延时,消息队列性能高。
提供全托管服务,用户只需专注于业务开发,无需部署运维,更专业、更弹性、更可靠。
全托管服务 紫光云消息队列Kafka有专门经验丰富的运维团队进行部署和维护,用户只需专注于业务本身,支持对实例和节点进行巡检、监控。
|
弹性扩展 用户可以按需自动扩展队列,按需计费,不会造成资源的浪费。
|
高性能 毫秒级消息投递;支持亿级消息堆积,且不影响队列性能。
|
独占式体验 紫光云消息队列Kafka实现物理隔离,实例之间互不影响,提供多种规格供用户选择,即开即用。
|
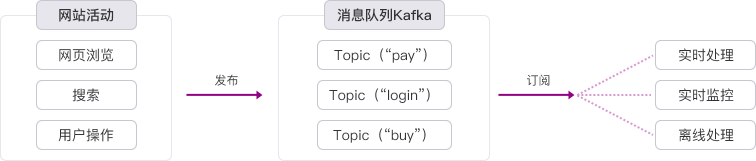
| 日志分析 应用程序可以把日志集中发布到Kafka中,无需记录到本地,再由专门的日志管理程序从Kafka中取出进行处理。对于多个进程读写同一个日志文件的场景,可以避免日志文件的加锁操作。也可以对Kafka中的日志进行实时分析。构建应用系统和分析系统的桥梁,将它们进行解耦。 特点 采集日志时业务无感知 Hadoop等离线仓库存储和Storm/Spark等实时在线分析对接
|
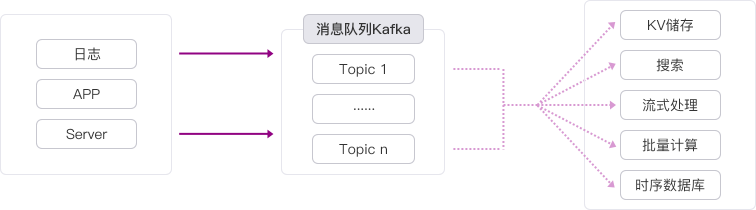
| 数据中转 近年来KV存储(HBase)、搜索(ElasticSearch)、流式处理(Storm/Spark Streaming)、时序数据库等等专用系统应运而生,产生了同一份数据集需要被注入到多个专用系统内的需求。利用Kafka作为数据中转枢纽,同份数据可以被导入到不同专用系统中。
|
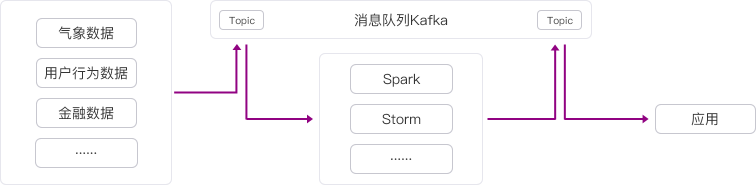
| 流计算处理 由于数据产生快、实时性强、数据量大,所以很难统一采集并入库存储后再做处理,这便导致传统的数据处理架构不能满足需求。而Kafka以及Storm/Samza/Spark等流计算引擎的出现,可以根据业务需求对数据进行计算分析,并把结果保存或者分发给需要的组件。
|