

纷享销客CRM
纷享销客连接型CRM为企业提供销售管理、营销管理及服务管理为一体的移动化客户全生命周期管理,助力企业实现外部业务、内部员工、上下游伙伴之间的互联互通,构建连接企业内外的业务价值。

广州九一乐维科技有限公司
客服热线: 020-28192830
工作时间: 7*24h
电子邮件: Market@lwops.cn
乐维智能监控是面向大中小型企业进行一体化监控、管理系统,帮助各行各业建立完整的监控、运维体系。从而彻底改变错综无序的IT服务现状,提高IT团队的生产效率。
V5.0
Linux
管理与监控
a) 产品描述简介
乐维智能监控贯穿了ITIM和CMDB,通过整合监控数据、告警数据、配置数据、业务关联关系、统一知识库等多维数据,研发了人工智能算法平台,实现业务洞察、动态基线、故障定位、异常检测、智能告警、影响分析等场景,满足各行各业IT运维从救火式到主动式的升级,提高服务效率。
b) 产品特点、功能介绍
1、特色:不重复造轮子、不绑架用户;自动发现CMDB配置项和资产数据,视图展示IT资源的分配和使用状况;以ITIL、DevOps、AiOps为发展方向,保证代码向后兼容、保证产品可持续性。
2、功能简介:
(1)基础架构监控
操作系统监控:针对CPU、内存、硬盘等各个指标多维度的监控,支持Windows、IBM、
AIX、Linux、HP Unix、Sun Solaris、Novell SUSE、FreeBSD、Red Flag等操作系统,
提供操作系统所运行的服务自动发现和状态监控的功能。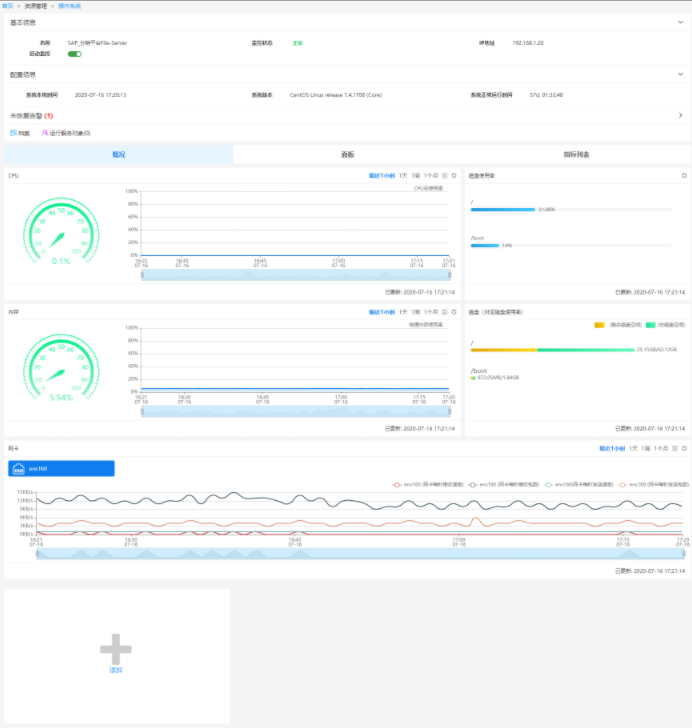
网络设备监控:针对运行状态、CPU使用率、内存使用率、端口发送和接收流量、速
率、丢包率等指标监控,细化至每个端口,实时查看指标状态曲线图;网络设备包括交
换机、防火墙、负载均衡等,用户可以对网络设备的类型进行管理上的分组。
数据库监控:针对数据库服务状态、死锁数、BUFFER命中率、作业数、用户连接数、
文件大小、文件启动事务数、查询状态和发送状态等指标监控;支持PostgreSQL、
Microsoft SQL Server、Oracle、Sybase、MySQL、DB2等数据库,用户可以对数据库的
类型进行管理上的分组。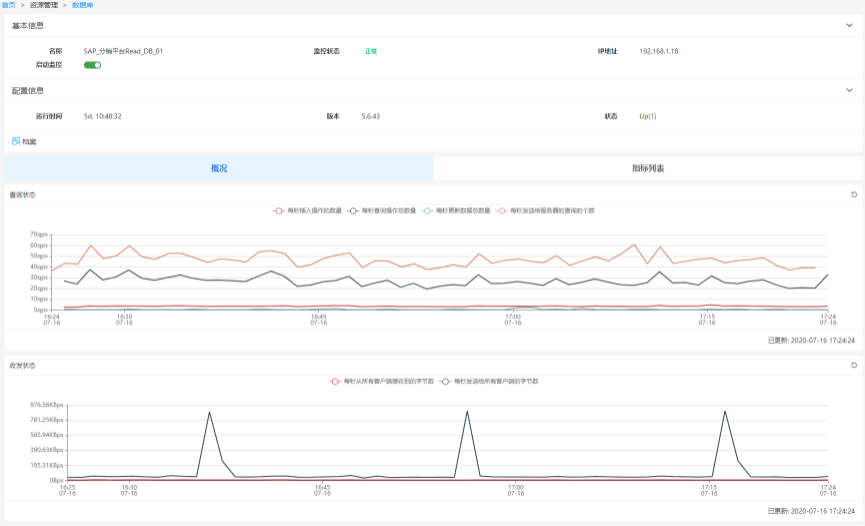
存储:针对运行状态、指示灯、IO速率、raid状态、温度、电源、风扇等指标监控,支
持监控IBM、惠普、戴尔、华为、联想、浪潮、曙光、H3C等主流品牌。
虚拟化监控:针对运行状态、CPU使用率、内存使用率、磁盘使用率、磁盘总量和使用
量、IO速率等指标监控,支持vmware等多种类产品,包括VMware、Citrix、Hyper-V、
OpenStack等主流虚拟化平台。
中间件:包含但不限于IIS、Tomcat、Apache、WebLogic等中间件,监控内容包含各类
指标数据。
Web:及时解决访问慢或者访问异常的页面,支持响应时间、状态码、速率、错误信息
等指标监控,提供曲线图分析功能,时间点可自行设置。
链路:支持链路带宽、使用率等指标监控,支持Rping(网络设备之间发起的ICMP探
测)、代理proxy,指标包括:延时、抖动、丢包率等。
云平台:支持主流公有云(腾讯云、华为云、阿里云、AWS等)、私有云、混合云。
容器:支持容器自动发现,实时监控容器状态、资源使用情况、容器中各种服务的状态。
(2)业务地图:以业务系统为核心,计算关联的网络、主机、数据库、中间件等故障
影响范围,实现业务故障的快速定位和影响分析。提供单个业务健康度、繁忙度、可用度分析能力。
(3)网络拓扑:提供网络拓扑自动发现功能,可自行过滤、筛选、拖拽生成所需的网
络拓扑,同时可在拓扑图上显示设备、链路的静态信息和动态指标,如有异常,可直接在拓扑图上高亮闪烁显示。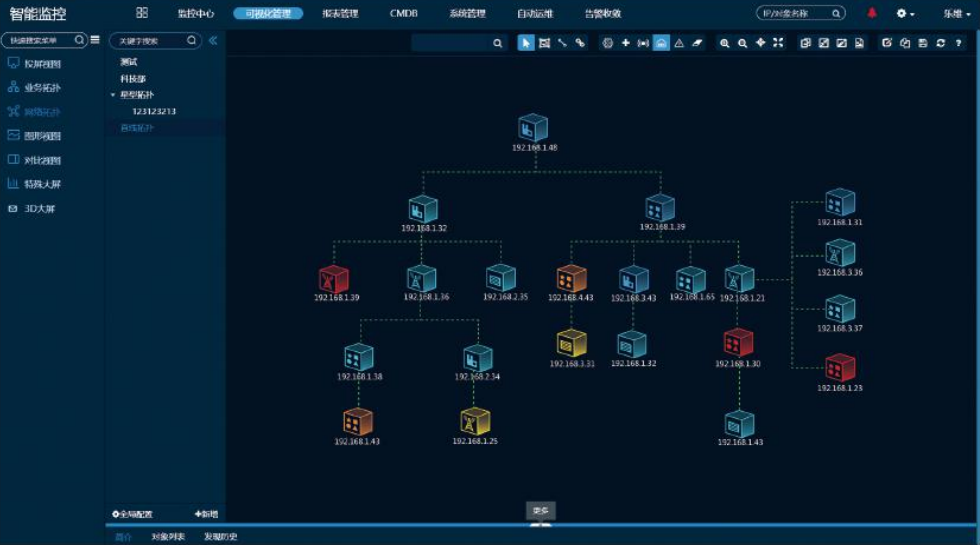
(4)可视化大屏:提供大屏背投视图功能,实时掌控监控状态,对不同的监控资源进
行体现,将监控系统背投到电视屏幕,支持多种主题、多样式分布,多颜色和格式等设置。
(5)多样化告警推送:提供告警通知记录功能,针对告警标题、接收方式、接收人、
消息内容、发送时间、发送结果和失败原因进行记录和统计。
(6)专家智库:提供专家管理知识库功能,支持针对告警运维处理方式图表化管理。
(7)统计报表:提供日报、周报、月报统计报表功能,针对一日、一周、一月的运维
状态统计形成报表。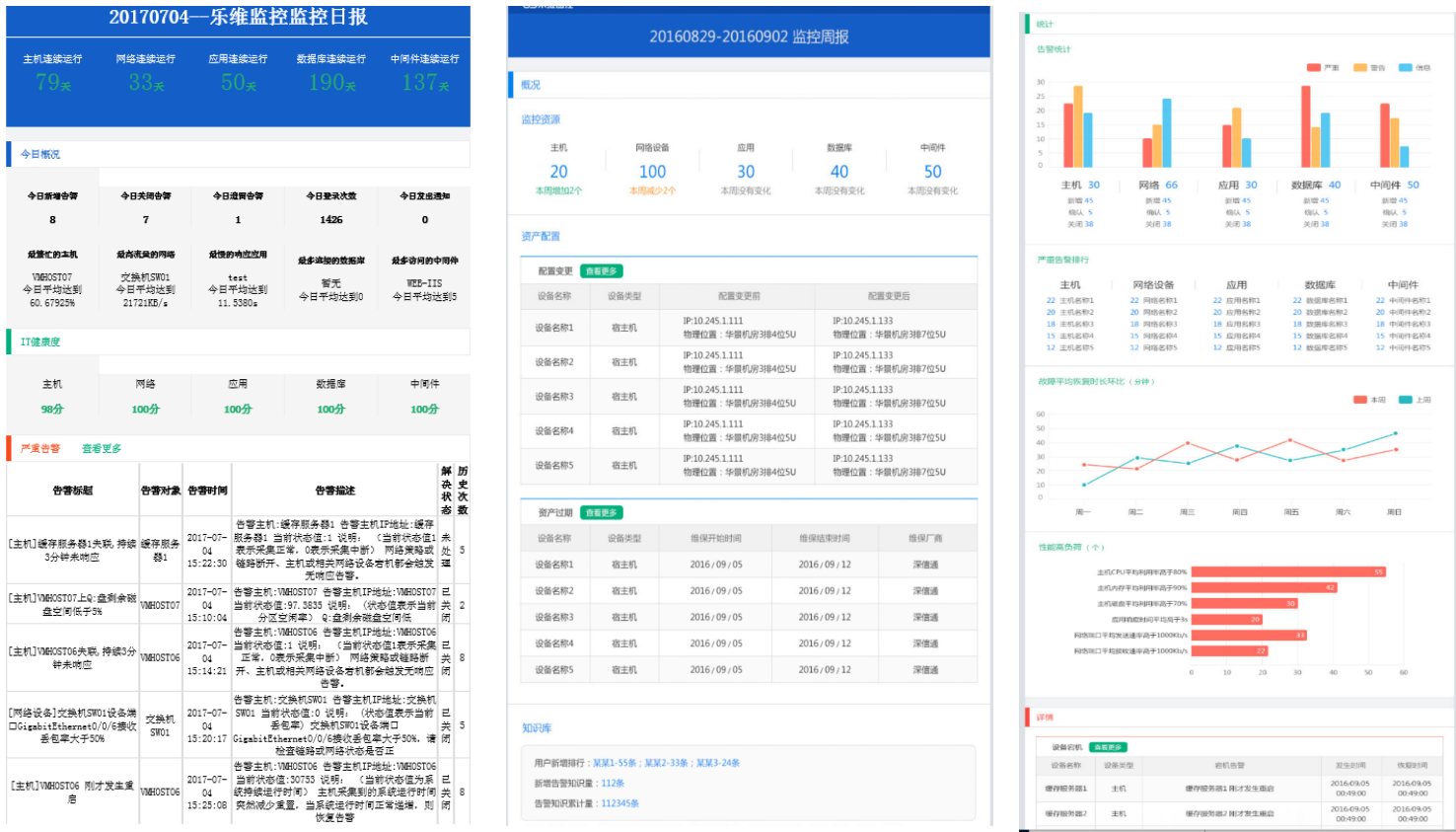
(8)资产视图:提供资产对象名称、当前状态、访问方式、设备类型、型号、CPU详
情、内存容量、硬盘容量、重要级别、供应商、采购时间、有效时间等多种属性管理,支持属性自定义。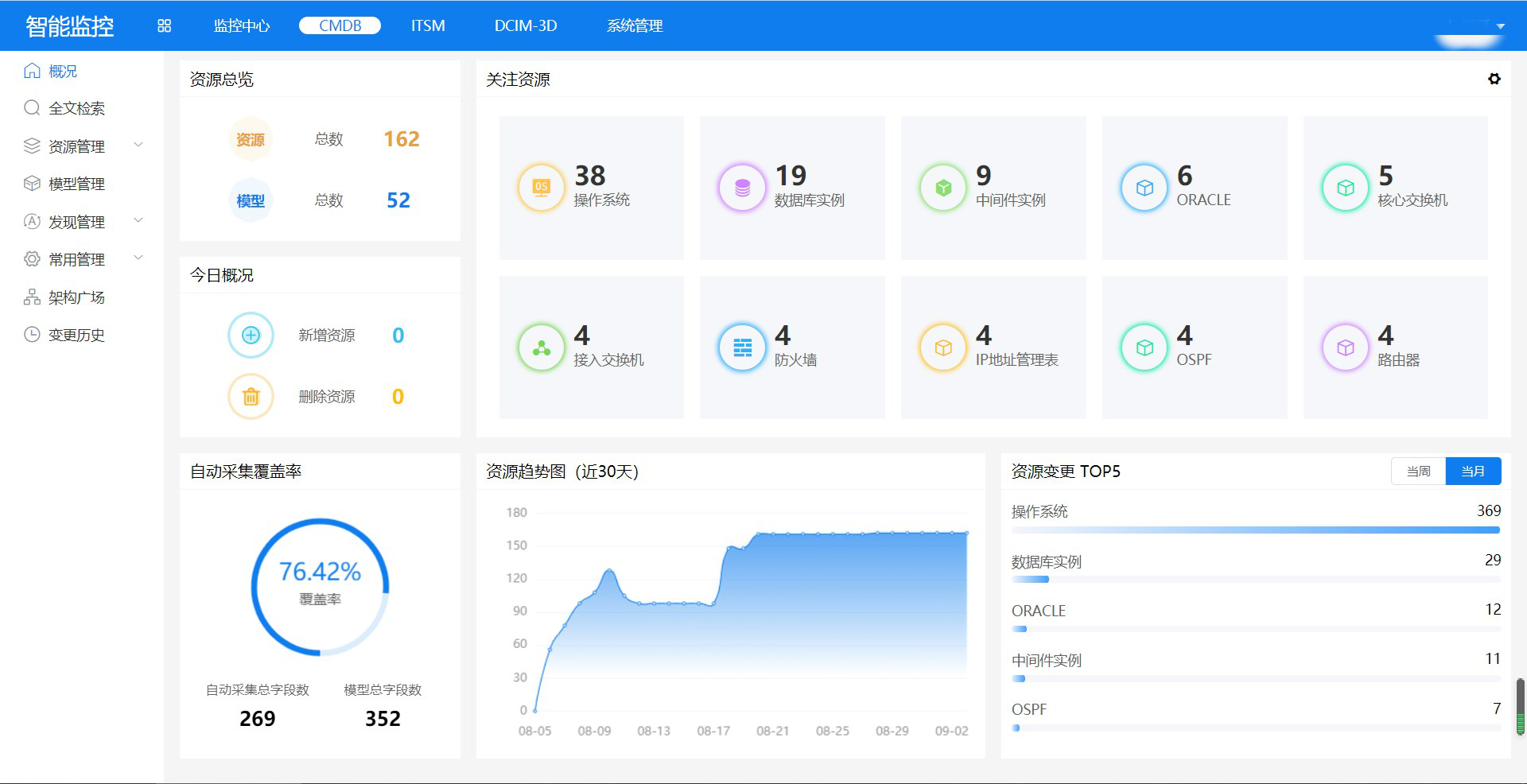
(9)资产列表:支持根据对象名称、负责人等信息搜索资产列表,可批量导入/删除已
下架设备和批量编辑资产信息,实时展示资产设备纳管状态,支持自定义显示设备信息的列和资产CI项。
(10)资产变更记录:支持根据用户、对象、IP等信息查询资产变更记录。
(11)后台配置:模型管理模板关系权限管理配置日志
c) 应用指南(应用官网、开源社区、使用指南、License说明等)
应用官网:www.lwops.cn
社区:QQ群177428068
使用指南:附件
| License-监控数量 (元/年) | 专业版 (监控) | 企业版 (监控+CMDB) |
|---|---|---|
| 50 | ¥28,500.00 | ¥35,625.00 |
| 100 | ¥54,000.00 | ¥67,500.00 |
| 150 | ¥76,500.00 | ¥95,625.00 |
| 200 | ¥96,000.00 | ¥120,000.00 |
| 250 | ¥112,500.00 | ¥140,625.00 |
| 300 | ¥126,000.00 | ¥157,500.00 |
| 350 | ¥136,500.00 | ¥170,625.00 |
| 400 | ¥144,000.00 | ¥180,000.00 |
| 450 | ¥148,500.00 | ¥185,625.00 |
| 500 | ¥150,000.00 | ¥187,500.00 |
1. 项目名称
武汉市某医院统一监控平台建设
武汉某医院始建于1956年,1997年获批成为湖北省首家“三级甲等”医院,2018年成功复评。历经六十余年的建设发展,现已成为融医疗、教学、科研、预防、康复于一体的现代化医院。先后获得“第一批国家特色医院文化医院”、“湖北省首批医务社工试点医院”、“全市百佳法治建设示范单位”、“市级文明单位”等称号。
中心现有两个院区,出院患者数达万余人次。连续举办具有国际影响力的中美、中法等精神分析培训项目,积极承办世界卫生组织(WHO)、国际精神分析协会(IPA)等国际组织的学术交流活动,获广泛关注,影响深远。
随着设备的逐年老化,故障率逐渐提高,对业务支撑系统的风险逐年加剧,没有一套统一的运维监控平台。首先,IT运维部门不能提前预知故障隐患,提前排除可能发生故障的隐患,避免形成故障;其次,当故障发生时,IT人员不能第一时间发现故障;再次,IT人员分析处理故障,没有一个从IT基础架构到业务可用性的全栈监控工具,靠人工逐层分析,效率低下;最后,排查故障之后,下次再出现类似的故障时,没有有效的、可持续消费的知识记录。
综上,为了解决业务支撑系统全方位的保障,基于Zabbix开源平台建设一套统一的、开放的、自主的,可持续发展全链路运维监控平台已成为必要。
该医院两个院区,通过内网互联,另外医院与医保局、卫生局有专网连接,保障卫生审计和医保数据对接。
内部信息化建设,搭建了VMWare虚拟化私有云,保障其信息基础设施高可用性,通过配置一台宏杉存储、两台华为存储提供存储资源,上层采用了华三X86服务器提供计算资源。两个院区通过汇聚交换机与核心交换机进行互联,另外接入层交换机保障了门诊、行政、住院区进行三级互联。
同其他医院一样,该医院核心系统为HIS,HIS系统采用单独服务器部署,数据库搭建Oracle11g rac,分布于两台物理服务器上。另外虚拟化系统搭建一台备机,通过Oracle dataguard技术实现数据同步。另外pacs系统部署在虚拟化上,通过VMWare datastore提供大容量存储,进行文件服务支持。
医院系统作为社会建设重要部门,历来高度重视信息化基础建设,为保障信息化高可用性,重点保障his 系统可用。该医院由专业维护团队进行日常健康巡检、系统维护、故障处理。在相关运维人员精心维护中,还是出现了不同等级的故障事件,如出现专网中断时,等到患者就医处理时才发现。夜间系统出现资源使用紧张时,等到白天工作期间高峰时出现紧急故障事件,以及急诊时出现系统异常,需单独处理等等。不确定性的故障风险,为医院运行带来了不便,加大了医护人员工作程度,也对社会造成了不好的影响。
为保障该医院信息化系统更加完善,为医护人员提供有效帮助、更高效率实现医护工作,同时更好的为社会提供服务,缓解医患关系。在现有信息化相关维护前提下,有必要建立一套针对信息化的监控平台,做到及早发现故障、提早判断预知故障及时处理,以及合理利用信息化基础资源,达到最大化资源使用,同时为信息化建设提供未来建设提供合理依据,使得医院系统信息化建设健康发展。
结合武现有信息化建设架构,建设统一监控平台部署内容如下:
1、集中监控:包括从IT基础架构到业务系统的可用性、性能、日志等指标监控;
2、集中告警:集中告警展示、告警分发、告警处理等全生命周期管理;
3、可视化视图:可自动发现的网络拓扑、业务地图、投屏视图、图形视图、一览视图等可视化功能;
4、多样性报表:支持自定义、多维度、多指标报表统计功能;
5、大屏展示:大屏幕集中监控实现自定义展示页面;
本项目倡导的是从硬件、主机、网络设备、数据库、中间件、应用、业务系统、存储、虚拟化的一站式运维管理平台,可以实现整个业务系统和IT 基础架构的统一集中管理。
前期监控对象搜集,通过和客户交流、沟通,搜集相关需求及本次需要纳入监控的相关对象分类,包括操作系统、网络设备、数据库、中间件、虚拟化、服务器、存储设备。
主机系统:IP地址,系统类型、业务名称等
网络设备:设备名称、设备类型、设备团体名、管理IP
数据库:数据库类型、数据库版本、监听端口、实例名
中间件:中间件类型、中间件版本、部署路径、IP地址,服务端口
虚拟化:虚拟化类型、型号、管理IP地址,用于监控的账号密码
服务器:服务器品牌、型号、带外管理地址、团体名
存储:存储品牌、型号、管理口地址、团体名、用于监控的账号密码

完成相关对象搜集后,结合本次监控对象的数量、类型、监控频度,综合判定本次架构设计,制定详细实施计划。
该医院本次监控对象为包括涵盖了操作系统、网络设备、数据库、中间件、虚拟化、服务器、存储,总体监控对象在200个以内。
定义本次系统架构部署如下:

架构说明:
两台服务器,分别部署MySQL数据库,采用MySQL master-slave实现主备方式实现数据库高可用,监控平台服务器部署在服务器1,主要功能为采集监控对象数据存放在主数据库,web部署在服务器2上,用于提供上层集中访问。
| 角色 | 操作系统 | 磁盘大小 | CPU | 内存 | IP地址 | 主机个数 | 备注 |
|---|---|---|---|---|---|---|---|
| 监控系统 | CentOS7 | 300G | 8核 | 8G | 一个IP 地址 | 1 | 守护进程 |
| Web | CentOS7 | 300G | 8核 | 8G | 一个IP 地址 | 1 | 守护进程 |
完成监控平软件部署后,根据搜集表进行分批次添加监控对象。
由于操作系统需要安装agent用于数据采集,结合现场部署环境、调整好安装脚本,配置好serverIP地址,采集方式后,实现快速一键安装agent。
Linux 首次安装需要通过root权限,完成首次安装后后续可以通过创建的zabbix用户实现数据采集aget开启或关闭,另外通过配置定时任务计划,判定agent进程是否正常,每五分钟检查一次,若检查到agent进程异常,即调用自动开启脚本将agent开启,省去后续agent维护工作,实现自动化。
Windows首次安装也需要通过管理员权限,完成后实现服务自动启动。
由于服务器不同厂商、不同型号存在内部mib库不一致情况,前期搜集时即核对模板样例,现有模板可直接准备,导入备用。本次监控服务器、存储基本属于常规型号,现有模板基本涵盖,宏杉存储模板没现有模板,通过客户协调获取到存储mib库,快速制作模板,体现了zabbix 快速定义模板的灵活性。
根据搜集该医院网络设备,主要为华为网络设备、华三网络设备,核对了为模板库,都有现有模板,结合前期信息搜集时的管理IP地址、团体名,实现快速添加监控对象。
该医院虚拟化使用的时VMWare ,并搭建了vcenter统一管理。结合乐维模板监控即采集python脚本,实现对象添加后,自动发现出宿主机、虚拟机、datastor三个主要对象并自动发现出其层级对应关系。
该医院数据库主要为Oracle 。监控Oracle数据需要在数据库创建用于监控的用户,并完成授权,保障用于监控的用户可select数据库相关性能视图,获取整个数据库运行状况。其操作存在对数据库变更,通过和客户反馈、沟通并确认风险等级及对应措施后,完成Oracle数据库纳入监控,查看监控平台数据库运行状况正常。
该医院属于医疗行业,其网络结构与医保局、卫生局存在关联、且这两条线路的通讯状态对于医院运行至关重要,因此单独使用监控平台链路添加,且这两条网络对端设备不在本地,不能实现监控那关,通过与医保、卫生专网接入的交换机,配置NQA,实现本段设备探测对端网络的链路监控,获取链路健康状况、带宽利用率、链路丢包率等信息。
网络拓扑是整个信息化的交通枢纽,网络的影响通常都是区域性影响,因此网络拓扑的展示可直观的看到当前网络健康状况,监控平台网络拓扑配置lldp 实现网络拓扑自动发现、自动关联网络设备生成拓扑图
完成监控对象纳管后,通过和客户沟通、培训,进一步确认相关监控阈值配置,即根据客户实际情况配置告警阈值,当监控指标达到阈值设置后,即触发告警。同时将不同阈值对应到不同告警级别,分别为紧急、严重、一般这几个常用级别。
紧急故障:
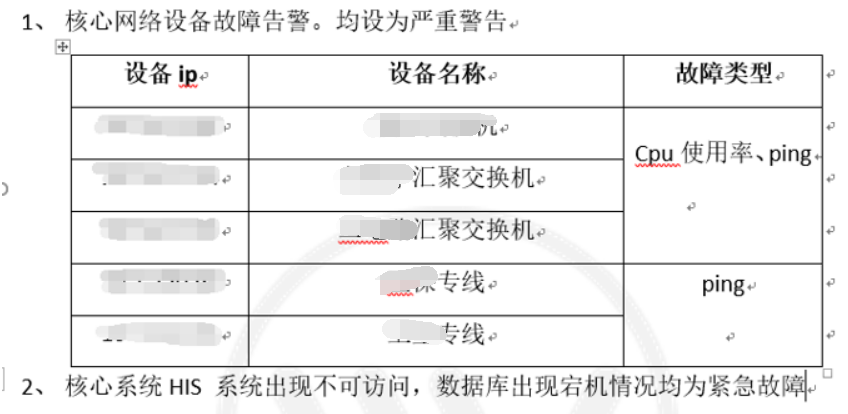
严重故障:
1、各区域网络故障,影响较多人办公的故障。主要为门诊楼和办公楼网络出现故障

2、服务器发生重启或者宕机。
服务器告警指标:ping 、cpu使用率达到80%以上、内存使用率95%、磁盘空间使用率达到98%
3、数据库重点规则
数据库连通性、表空间使用率95%、数据库文件系统使用率95%
一般告警
1、网络设备一般告警
2、主机系统相关资源使用情况。
投屏展示通常可直观、简介的查看整个IT资源或某个业务的实际情况,经过和客户交流沟通后,确定本次创建两个投屏展示,分别如下
5.5. 大屏展示配置


IT运维通常会有相应统计信息,包括日产产生的告警信息,及相关业务性能分析,本次根据该医院建设需求,创建应用系统基础资源使用性能报表,并自定义设定成周报模式,每周会自动生成报表。

6. 方案价值
实现信息化基础资源全覆盖监控,保障了监控自动化管理,通过设置配置即可达到相关调整。降低人工成本,使用运维人员去做对业务更有价值的工作。
监控对象集中展示
自动分类展示,实现不同对象的统计、健康状况、告警数量,从整体上可直观查看当前所有IT资源对象的,同时从整体上查看当前对象的CPU top、内存使用率top等,另外可整体直观看到当前整个IT状况是否正常,以及每日产生告警数量、告警恢复情况。
为运维人员提供更准确、更直观的整体状况查看。无需单独去登录每个系统、每个设备进行繁琐的巡检工作。

运维人员可查看最近6小时、最近12小时及最近24小时告警,可了解整个资源运行状况,避免信息化资源出现告警隐患而人员未关注到时告警遗漏,更加准确的反馈了整体健康状况,分别从不同等级、告警事件、告警时长直观的呈现,让运维人员心中有数。
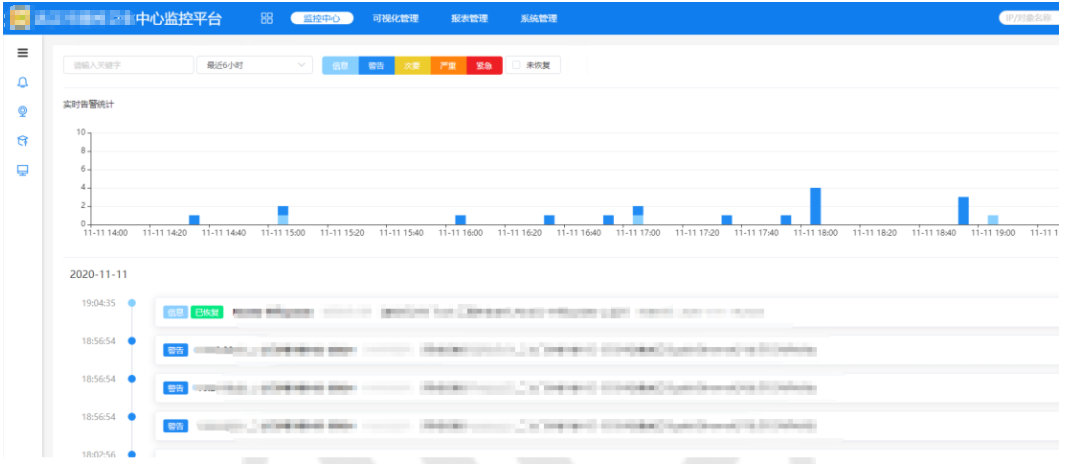
另外,对于以往的告警也可有迹可循,当一个告警反复出现,或在每日某一个时间段出现时,可根据全部告警,进行综合查看,如一个一般级别告警,但是反复出现也需要引起关注。

集中告警功能包含了实时告警、全部告警、告警统计等多个维度,匹配运维人员使用习惯,做到告警无遗漏、告警分等级,告警可追溯。从整体上减轻了运维人员工作,且真正做到7* 24小时实时监控,为运维管理工作代理了直观的价值。
运维管理通常需要直观呈现,重点关注的对象,通过配置网络拓扑、业务拓扑,并通过投屏配置方式呈现,及时反映重点关注的如网络健康状况、专线链路状况等。当出现异常时,可快速定位故障,大大缩短故障定位、排查时间,为解决故障提供了有效依据。将前端业务影响降至最低。为整个医护工作带来了最大的便利。
运维工作除了对日常信息化健康运行关注外,还需要对整体资源使用情况做到合理分配,当资源需要进行调整时,可有效进行整改、达到资源最大化利用率。也可为单个业务系统创建报表,提供日报、周报,展现趋势数据提供性能分析。
另外,对于整个信息化基础架构运行状况,也可通过报表的告警统计,不同维度查看告警统计,操作系统告警统计、网络设备告警统计,以不同类别、不同等级分别展示。为信息化建设可持续发展提供了有效帮助。
1. 通过IT资产全面梳理、全栈监控、实时告警等新型智能运维手段,建设出一套完善且灵活的成熟运维体系,告别传统“救火”式运维,运维效率提升10倍,企业运维成本降低超过50%。
2. 为医院提供更坚实的后勤保障,更加有效的保障医护人员日常工作,使得医护人员更加顺心的工作,进一步拉近医患关系,为社会提供更好的服务。
3. 提供更有效的数据依据,推进医院信息化建设可持续发展,让信息化资源更合理的应用、全面应用,为信息化建设提供导向。